自旋锁是指当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态。 缺点如下: 在自旋锁基础上加入计数器,支持可重入 为了解决上面的公平性问题,类似于现实中银行柜台的排队叫号:锁拥有一个服务号,表示正在服务的线程,还有一个排队号 缺点: 自旋公平锁(保证FIFO),独占锁,不可重入 实现示例如下: 自旋公平锁(保证FIFO),独占锁,不可重入1. 背景
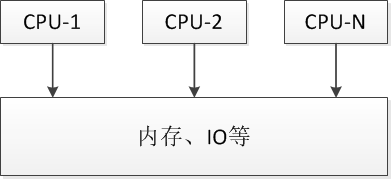
1.1. SMP(Symmetric Multi-Processor)
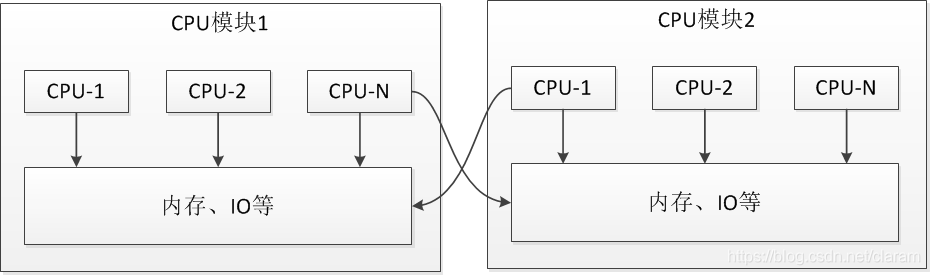
1.2. NUMA(Non-Uniform Memory Access)
2. 实现原理
2.1 自旋锁(Spin Lock)
自旋锁适用于锁保护的临界区很小的情况,临界区很小的话,锁占用的时间就很短。
简单自旋锁实现示例:public class SimpleSpinLock implements Lock {
//利用CAS操作,解决多线程并发操作导致数据不一致的问题
private final AtomicReference<Thread> owner = new AtomicReference<>();
@Override
public void lock() {
Thread currentThread = Thread.currentThread();
// 如果锁未被占用,则设置当前线程为锁的拥有者
while (!owner.compareAndSet(null, currentThread)) {
}
}
@Override
public void unlock() {
Thread currentThread = Thread.currentThread();
// 只有锁的拥有者才能释放锁
owner.compareAndSet(currentThread, null);
}
...
}
2.2 自旋可重入锁
实现示例:public class ReentrantSpinLock implements Lock {
//利用CAS操作,解决多线程并发操作导致数据不一致的问题
private AtomicReference<Thread> owner = new AtomicReference<>();
//加入计数器,支持可重入
private int count = 0;
@Override
public void lock() {
Thread currentThread = Thread.currentThread();
//如果锁被当前线程占用,则计数器+1
if (currentThread == owner.get()) {
count++;
return;
}
// 如果锁未被占用,则设置当前线程为锁的拥有者
while (!owner.compareAndSet(null, currentThread)) {
}
}
@Override
public void unlock() {
Thread currentThread = Thread.currentThread();
if (currentThread == owner.get()) {
//count大于0,说明锁被占用多次,执行-1
if (count > 0) {
count--;
} else {
//执行锁释放
owner.compareAndSet(currentThread, null);
}
}
}
...
}
2.3 排队自旋锁
每个线程尝试获取锁之前先拿一个排队号,然后不断轮询锁的当前服务号是否是自己的排队号,如果是,则表示自己拥有了锁,不是则继续轮询
实现示例:public class TicketLock {
private AtomicLong serviceNum = new AtomicLong();//服务号
private AtomicLong ticketNum = new AtomicLong();//排队号
public long lock() {
//首先原子性地获得一个排队号
long myTicketNum = ticketNum.getAndIncrement();
// 只要当前服务号不是自己的就不断轮询
while (serviceNum.get() != myTicketNum) {
}
return myTicketNum;
}
public void unlock(long myTicketNum) {
// 只有当前拥有者才能释放锁
serviceNum.compareAndSet(myTicketNum, myTicketNum + 1);
}
}
2.4 CLH锁
CLH的发明人是:Craig,Landin and Hagersten,基于名称简写而来
CLH锁是一种基于单向链表的高性能、公平的自旋锁
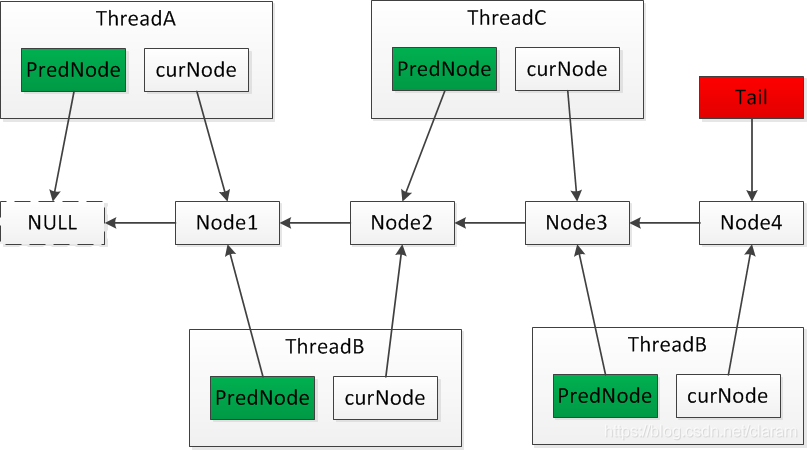
申请加锁的线程通过前驱节点的变量进行自旋,在前置节点解锁后,当前节点会结束自旋,并进行加锁。
在SMP架构下,CLH更具有优势,在NUMA架构下,如果当前节点与前驱节点不在同一CPU模块下,跨CPU模块会带来额外的系统开销,而MCS锁更适用于NUMA架构。
public class ClhSpinLock implements Lock {
private final ThreadLocal<Node> prev;
private final ThreadLocal<Node> node;
private final AtomicReference<Node> tail;
public ClhSpinLock() {
this.node = ThreadLocal.withInitial(Node::new);
this.prev = ThreadLocal.withInitial(() -> null);
this.tail = new AtomicReference<Node>(new Node());
}
/**
* 1.初始状态 tail指向一个node(head)节点
* +------+
* | head | <---- tail
* +------+
*
* 2.lock-thread加入等待队列: tail指向新的Node,同时Prev指向tail之前指向的节点
* +----------+
* | Thread-A |
* | := Node | <---- tail
* | := Prev | -----> +------+
* +----------+ | head |
* +------+
*
* +----------+ +----------+
* | Thread-B | | Thread-A |
* tail ----> | := Node | --> | := Node |
* | := Prev | ----| | := Prev | -----> +------+
* +----------+ +----------+ | head |
* +------+
* 3.寻找当前node的prev-node然后开始自旋
*
*/
@Override
public void lock() {
final Node node = this.node.get();
node.locked = true;
// 将tail设置为当前线程的节点,并获取到上一个节点,此操作为原子性操作
Node pred = this.tail.getAndSet(node);
this.prev.set(pred);
// 在前驱节点的locked字段上自旋等待
while (pred.locked) {
}
}
@Override
public void unlock() {
final Node node = this.node.get();
// 将当前线程节点的locked属性设置为false,使下一个节点成功获取锁
node.locked = false;
this.node.set(this.prev.get());
}
...
private static class Node {
private volatile boolean locked;
}
}
2.5 MCS锁
MCS 来自于其发明人名字的首字母: John Mellor-Crummey和Michael Scott
MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同,CLH是在前趋结点的locked域上自旋等待,而MCS是在自己的结点的locked域上自旋等待
它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题
实现示例如下:public class McsSpinLock implements Lock {
private final ThreadLocal<Node> current;
private final AtomicReference<Node> tail;
public McsSpinLock() {
this.current = ThreadLocal.withInitial(Node::new);
this.tail = new AtomicReference<>();
}
@Override
public void lock() {
Node node = current.get();
Node pred = tail.getAndSet(node);
// pred的初始值为null,所以第一个加锁线程,直接跳过判断,加锁成功
if (pred != null) {
pred.next = node;
// 在当前节点的locked字段上自旋等待
while (node.locked) {
}
}
}
@Override
public void unlock() {
Node node = current.get();
if (node.next == null) {
// 如果设置成功,说明在此之前没有线程进行lock操作,直接return即可;
// 如果失败,则说明在此之前有线程进行lock操作,需要自旋等待那个线程将自身节点设置为本线程节点的next,
// 然后进行后面的操作。
if (tail.compareAndSet(node, null)) {
return;
}
while (node.next == null) {
}
}
// 通知下一个线程,使下一个线程加锁成功
node.next.locked = false;
// 解锁后需要将节点之间的关联断开,否则会产生内存泄露ø
node.next = null;
}
...
static class Node {
volatile boolean locked = true;
volatile Node next;
}
}
3、 CLH锁与MCS锁比较
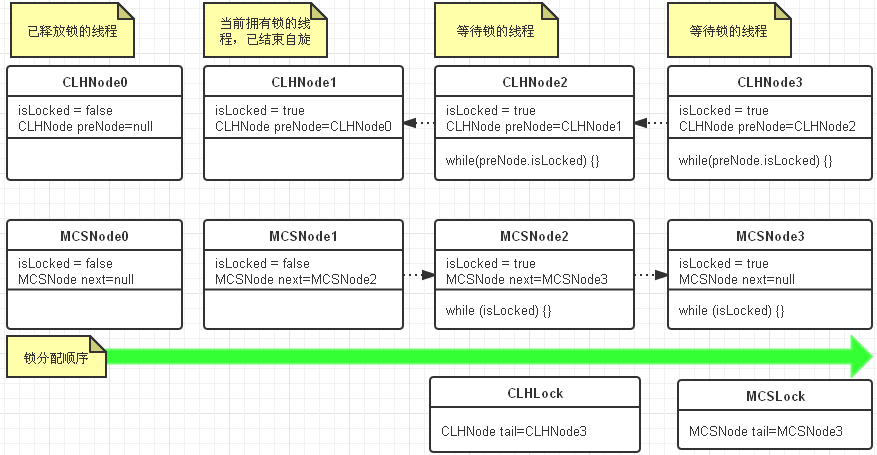
对比说明
原文