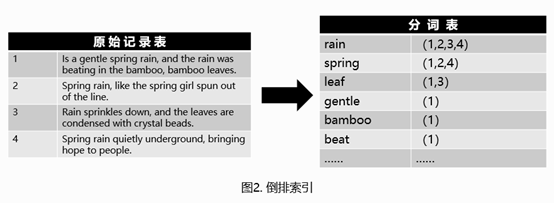
索引的生成分为两个部分: 索引创建及搜索流程如下图所示: ucene的基础层次结构由索引、段、文档、域、词五个部分组成。正向索引的生成即为基于Lucene的基础层次结构一级一级处理文档并分解域存储词的过程。 索引文件层级关系如图1所示: Lucene全文索引的核心是基于倒排索引实现的快速索引机制。 倒排索引原理如图2所示,倒排索引简单来说就是基于分析器将文本内容进行分词后,记录每个词出现在哪篇文章中,从而通过用户输入的搜索词查询出包含该词的文章。 问题:上述倒排索引使用时每次都需要将索引词加载到内存中,当文章数量较多,篇幅较长时,索引词可能会占用大量的存储空间,加载到内存后内存损耗较大。 解决方案:从Lucene4开始,Lucene采用了FST来减少索引词带来的空间消耗。 具体存储方式如图3所示: 倒排索引相关文件包含.tip、.tim和.doc这三个文件,其中: tip:用于保存倒排索引Term的前缀,来快速定位.tim文件中属于这个Field的Term的位置,即上图中的aab、abd、bdc。 https://segmentfault.com/a/1190000040371949
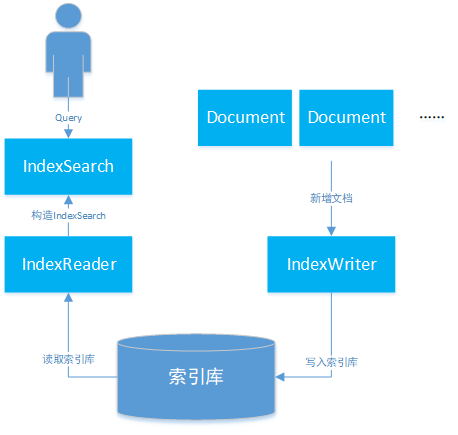
Lucene索引构成
正向索引
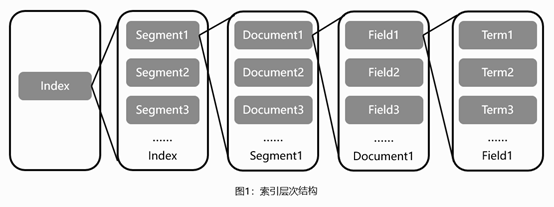
倒排索引
FST(Finite StateTransducers),中文名有限状态机转换器。其主要特点在于以下四点:
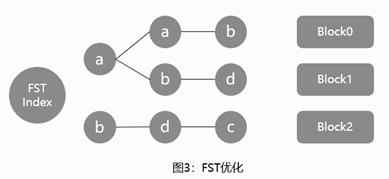
tim:保存了不同前缀对应的相应的Term及相应的倒排表信息,倒排表通过跳表实现快速查找,通过跳表能够跳过一些元素的方式对多条件查询交集、并集、差集之类的集合运算也提高了性能。
doc:包含了文档号及词频信息,根据倒排表中的内容返回该文件中保存的文本信息。原文