10-15 毫秒/传输数字是我们根据 Windows 和 SQL Server 工程师多年来的集体经验选择的非常近似的阈值。 通常,当数字超过此大致阈值时,SQL Server用户开始看到其工作负载中的延迟并报告这些延迟。 最终,I/O 子系统的预期吞吐量由制造商、型号、配置、工作负载以及可能的其他多个因素定义。 查看历史io数据 以下是在报告磁盘 I/O 问题时SQL Server观察到的常见等待类型的说明。 当任务在 I/O 请求中等待数据或索引页的闩锁 (缓冲区) 时发生。 闩锁请求处于独占模式。 当缓冲区写入磁盘时,将使用独占模式。 长时间等待可能表示磁盘子系统存在问题。 当任务在 I/O 请求中等待缓冲区的闩锁时发生。 闩锁请求处于更新模式。 长时间等待可能表示磁盘子系统存在问题。 在任务等待事务日志刷新完成时发生。 当日志管理器将其临时内容写入磁盘时,会发生刷新。 导致日志刷新的常见操作是事务提交和检查点。 长时间等待的 WRITELOG 常见原因包括: 发生以下某些 I/O 活动时发生: 在等待 I/O 操作完成时发生。 此等待类型通常涉及与数据页无关的 I/O, (缓冲区) 。 示例包括: 当备份任务正在等待数据或正在等待缓冲区存储数据时发生。 此类型并不常见,除非任务正在等待磁带装载。 https://learn.microsoft.com/zh-cn/troubleshoot/sql/database-engine/performance/troubleshoot-sql-io-performance#io_completion排查方向
磁盘
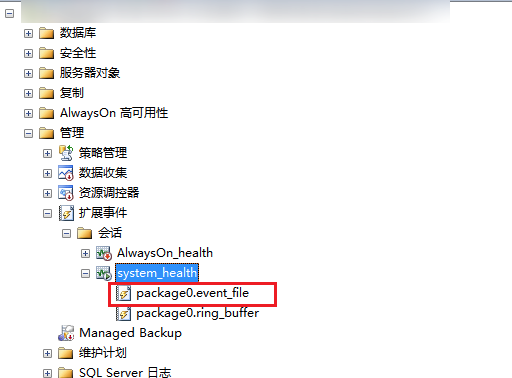
查看当前执行的语句,以及其等待时间
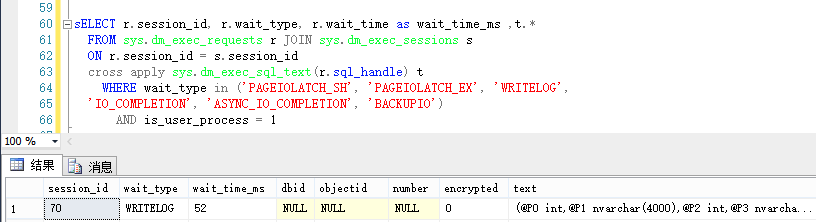
SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms ,t.*
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s
ON r.session_id = s.session_id
cross apply sys.dm_exec_sql_text(r.sql_handle) t
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG',
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')
AND is_user_process = 1
SELECT TOP 100 qs.last_execution_time, SUBSTRING(qt.TEXT, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.TEXT)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1),
qs.execution_count,
qs.total_logical_reads, qs.last_logical_reads,
qs.total_logical_writes, qs.last_logical_writes,
qs.total_worker_time,
qs.last_worker_time,
qs.total_elapsed_time/1000000 total_elapsed_time_in_S,
qs.last_elapsed_time/1000000 last_elapsed_time_in_S,
qs.last_execution_time,
qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
where qs.last_execution_time <= '2023-03-04 13:54:35.523'
-- ORDER BY qs.total_logical_reads DESC -- logical reads
ORDER BY qs.last_execution_time DESC
-- ORDER BY qs.total_worker_time DESC -- CPU time
有关 I/O 相关等待类型的信息
PAGEIOLATCH_EX
PAGEIOLATCH_UP
WRITELOG
ASYNC_IO_COMPLETION
IO_COMPLETION
BACKUPIO
参考文档